Introduction
In this post, I’ll be implementing logistic regression from scratch in Python. This is the second post in the “Machine Learning from Scratch” series, where I implement various machine learning algorithms without using external libraries like scikit-learn, PyTorch or TensorFlow.
Logistic regression is one of the most widely used classification algorithms and serves as a foundation for understanding more complex models like neural networks.
Logistic Regression
Logistic regression is a classification algorithm used to predict binary outcomes (0 or 1, True or False, Yes or No). Despite its name, it’s used for classification, not regression. The model uses the sigmoid function to map predicted values to probabilities between 0 and 1.
The sigmoid function is defined as:
σ(z) = 1 / (1 + e^(-z))
The model learns weights and bias that minimize the binary cross-entropy loss between predicted probabilities and actual labels.
Implementation
I’m using numpy for numerical computations and matplotlib for plotting. To test the model, I’ll use train_test_split and datasets from scikit-learn to generate some synthetic binary classification data.
The LogisticRegression class has the following methods:
__init__: Constructor to initialize the learning rate and number of iterations.fit: Method to train the model on the training data using gradient descent.predict: Method to make binary predictions on the test data.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
import matplotlib.pyplot as plt
class LogisticRegression:
def __init__(self, lr=0.001, num_iter=1000):
self.lr = lr
self.num_iter = num_iter
self.weights = None
self.bias = None
def fit(self, X, y):
num_samples, num_features = X.shape
self.weights = np.zeros(num_features)
self.bias = 0
for _ in range(self.num_iter):
linear_pred = np.dot(X, self.weights) + self.bias
predictions = self._sigmoid(linear_pred)
dw = (1/num_samples) * np.dot(X.T, (predictions - y))
db = (1/num_samples) * np.sum(predictions - y)
self.weights = self.weights - self.lr * dw
self.bias = self.bias - self.lr * db
def predict(self, X):
linear_pred = np.dot(X, self.weights) + self.bias
y_pred = self._sigmoid(linear_pred)
class_pred = [0 if y <= 0.5 else 1 for y in y_pred]
return class_pred
def _sigmoid(self, x):
return 1 / (1 + np.exp(-x))Now let’s test the model on synthetic binary classification data. I’ll use datasets.make_classification and evaluate the model’s accuracy on the test set.
def accuracy(y_test, predictions):
return np.sum(y_test == predictions) / len(y_test)
if __name__ == '__main__':
X, y = datasets.make_classification(
n_samples=1000, n_features=2, n_redundant=0,
n_informative=2, n_clusters_per_class=1, random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = LogisticRegression(lr=0.01, num_iter=1000)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
acc = accuracy(y_test, predictions)
print(f"Accuracy: {acc}")
fig = plt.figure(figsize=(8, 6))
plt.scatter(X_test[:, 0], X_test[:, 1], c=predictions, cmap='viridis', s=40)
plt.show()Let’s visualize the predictions:
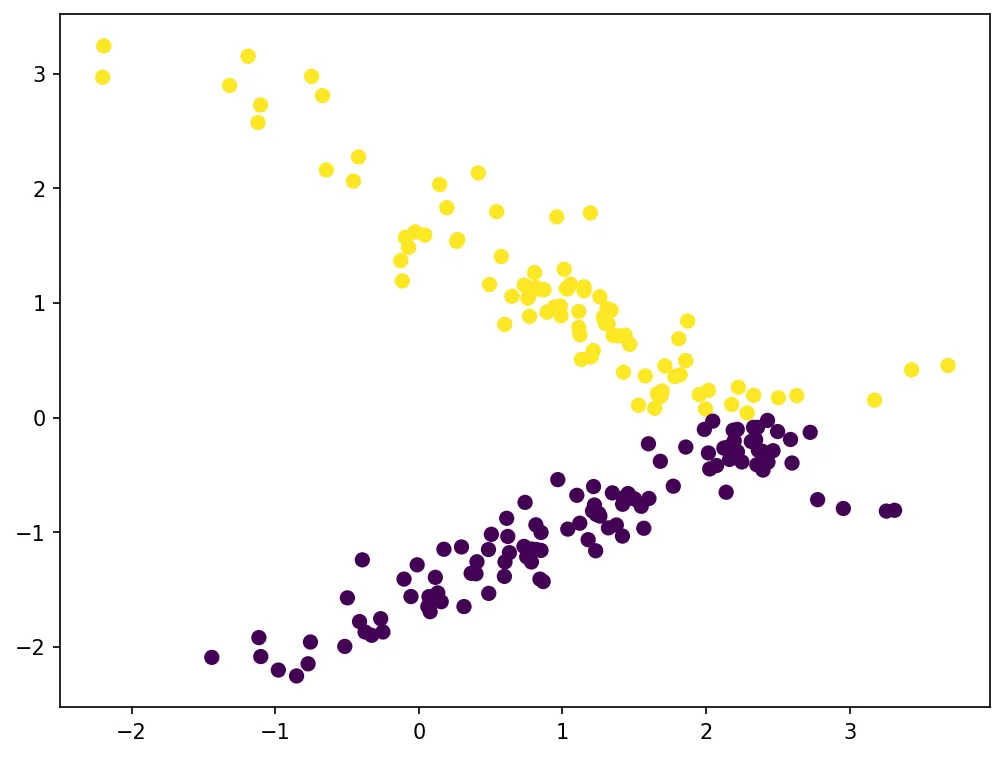
The model achieves high accuracy on the test set, correctly classifying most samples into their respective classes.
That’s all for this post. Thanks for reading!